软间隔支持向量机
在普通的支持向量机的讨论中,样本点或样本点映射后都是完全线性可分的。但是现实中存在问题
- 现实任务中往往很难确定合适的核函数是的训练样本在特征空间中线性可分
- 即使找到了某个核函数使得训练数据在特征空间线性可分,也很难断定这个貌似线性可分的结果不是因为过拟合造成的
由此,引入「软间隔支持向量机」
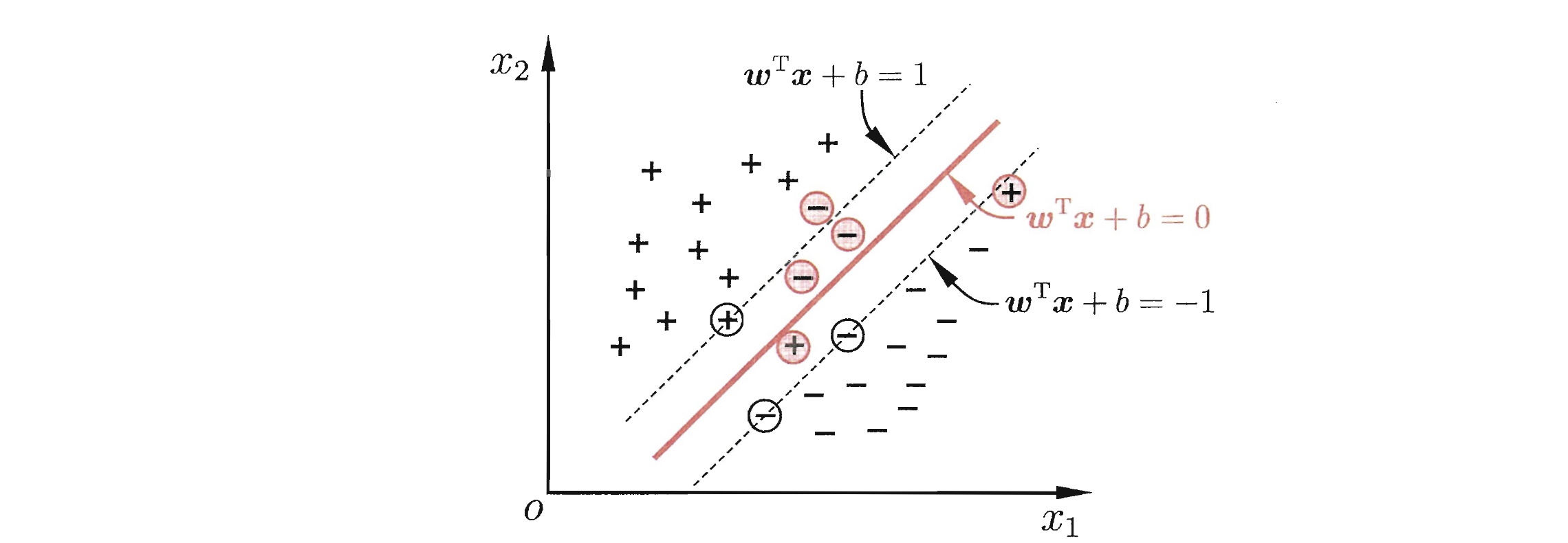
软间隔支持向量机允许 SVM 在一些样本上出错,即允许某些样本不满足约束
对于软间隔,在最大化间隔的同时,还希望不满足约束的样本尽可能少,所以优化目标式改写为
其中
惩罚因子
惩罚因子
由于
- hinge 损失
- 指数损失
- 对数损失
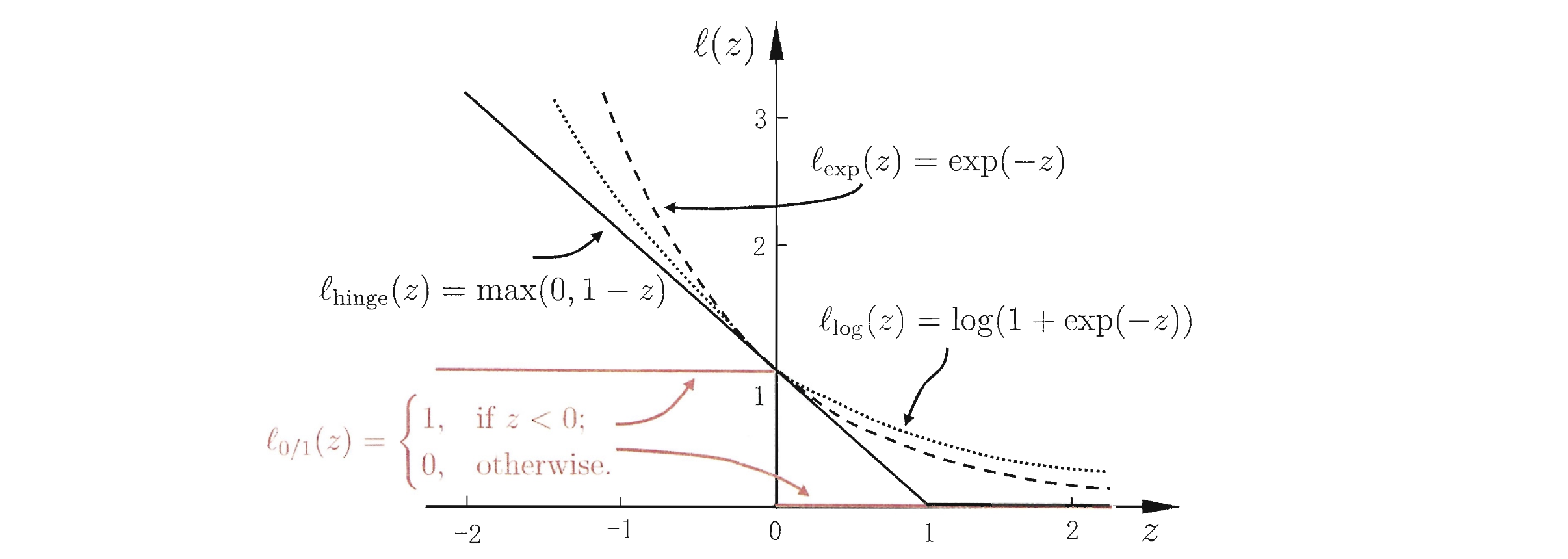
若用 hinge 损失代替
其中
变量
对于软硬间隔的对偶问题式对比可以发现,两者唯一不同是对偶变量的约束条件
- 软间隔要求
- 硬间隔要求
类似的,KKT 条件也会做出相应的变化。但是,软间隔支持向量机和硬间隔下一样,最终模型仅与支持向量有关。
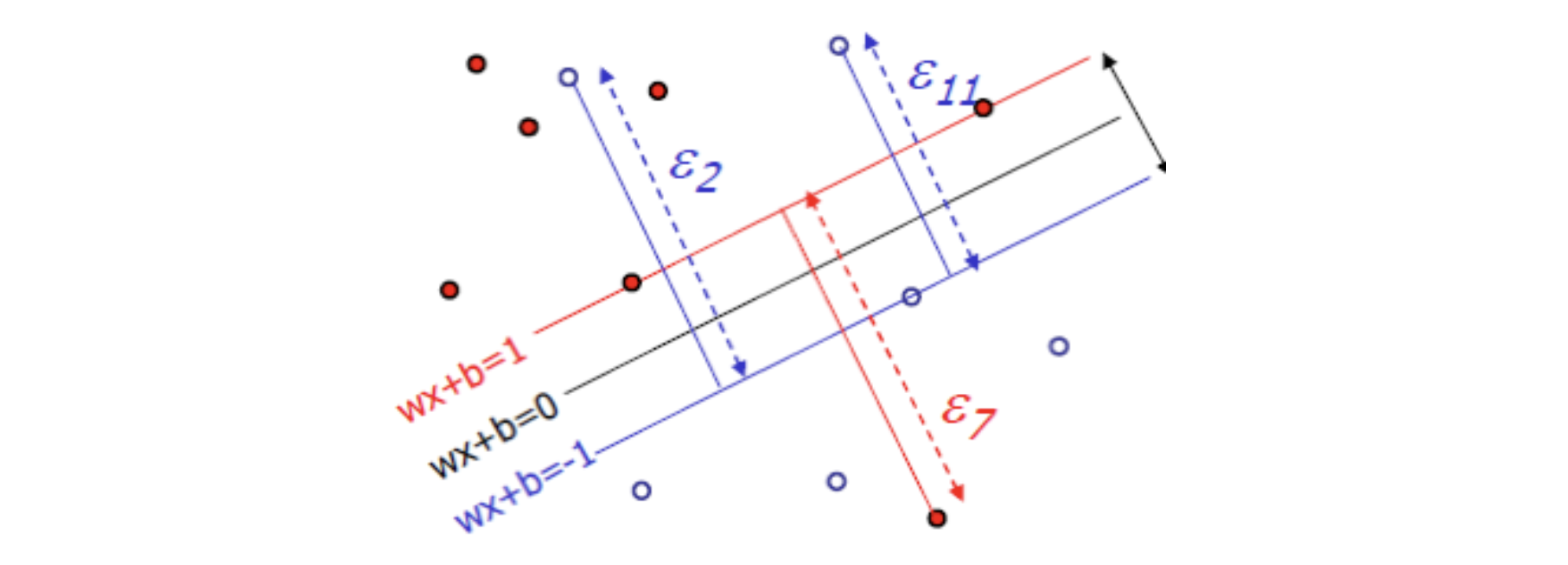
- 因为松弛变量是非负的,因此样本的函数间隔可以比1小。
- 函数间隔比1小的样本被叫做离群点,放弃了对离群点的精确分类,这对分类器来说是种损失。
- 并非所有的样本点都有一个松弛变量与其对应。只有“离群点”才有。
- 松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
- 放弃这些点也带来了好处,那就是超平面不必向这些点的方向移动,因而可以得到更大的几何间隔(在低维空间看来,分类边界也更平滑)。
Interactive Graph
Table Of Contents