MvM 策略
「MvM 策略」(Many vs. Many)是一种多分类学习学习策略。每次将若干个类作为正类,若干个其他类作为反类。OvO 和 OvR 可看作是 MvM 的特例。MvM 的正、反构造必须有特殊的设计,例如常见的 MvM 技术「纠错输出编码」 (Error Correcting)
- 编码:对
- 解码:
类别划分通过编码矩阵制定。常见的编码矩阵主要有二元码和三元码
如图 ECOC 二元码矩阵:分类器
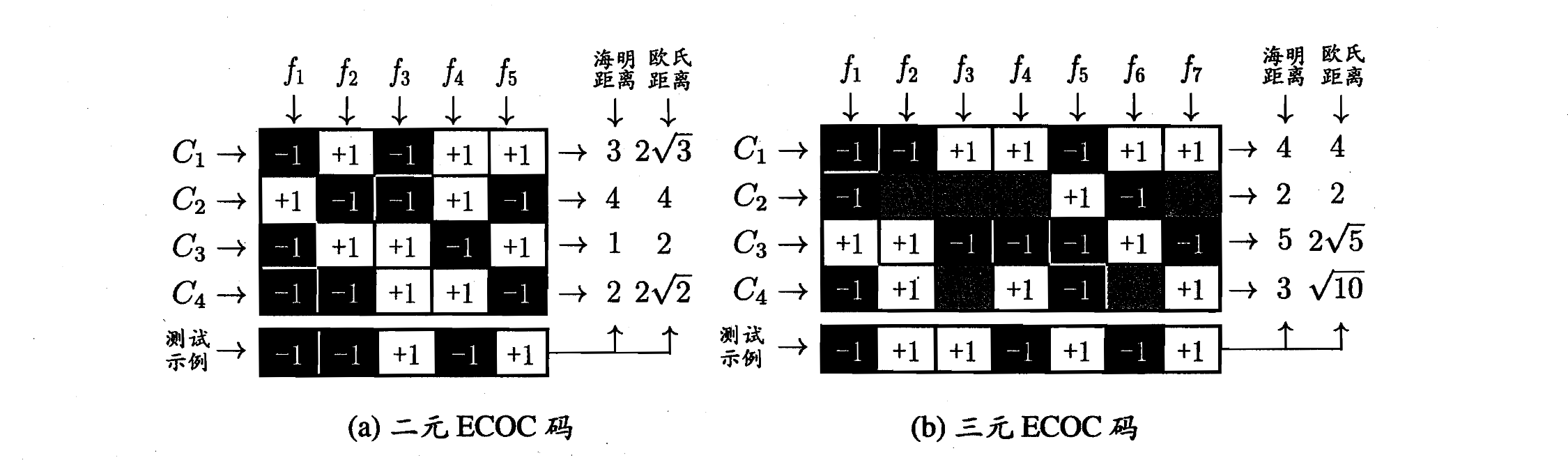
纠错输出码:ECOC 编码对分类器的错误有一定的容忍和修正能力。类别
一般来收,对于同一个学习任务,ECOC 编码越长,纠错能力越强,然而编码越长,对应计算、存储开销都会增大。另一方面,对于有限类别数,可能的类别组合是有限的,码长超过一定范围后就失去了意义。
Interactive Graph
Table Of Contents