一、模型架构
Unsupervised Adversarial Domain Adaptation for Implicit Discourse Relation Classification。作者:Hsin-Ping Huang和Junyi Jessy Li
本文基于Closing the Gap Domain Adaptation from Explicit to Implicit Discourse Relations,在其基础上作了改进。通过结合对抗差异域自适应和重建映射技术来保护了目标特征的差异性,从而实现了更好的隐式篇章关系分类。
对于无监督的域自适应,源域中的样本表示为
本文使用 ADDA 作为域自适应的潜在框架。ADDA 首先学习到源域分类过程中的差异表示,然后让目标域模仿源域分布,来学习对应的表示。当目标表示与其源相吻合时,将会执行一次「更新」。这过程类似于Generative Adversaial Networks加上了DANN的训练过程。
对于源域和目标域,ADDA学习到了不同的特征编码器,而不是使用同一个编码器,因此直观上来说,一个网络不需要同时处理来自两个域的实例。
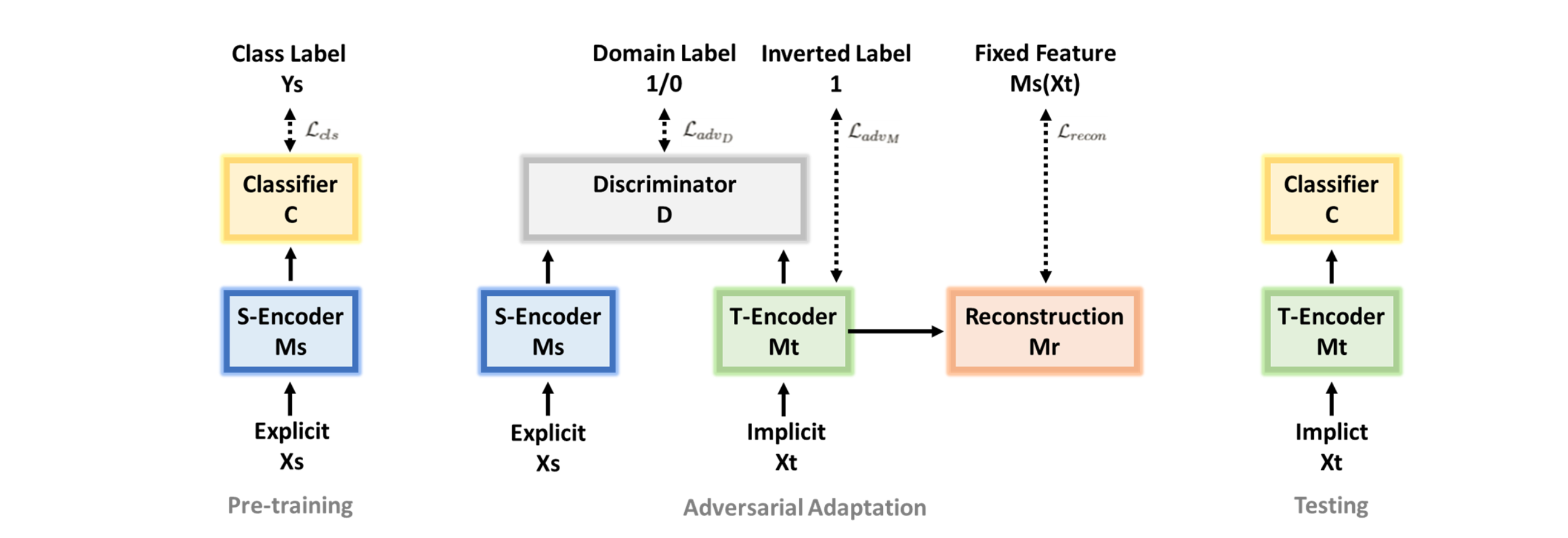
综上,模型的架构如下:
- 预训练一个源编码器
- 对抗适应:通过
- 最后,经过训练的目标特征空间能够匹配源的,此时源分类器
1. 基础编码器和分类器
首先在源域上做文章。在本文的语境下,就是先从显式数据中学得足够多的知识。这个过程可以通过预训练一个源编码器
1.1 编码器
1.2 分类器
分类器就是一个在编码器上的全连接层,然后以 softmax 分类层作为输出。源编码器
2. 无监督对抗域自适应
2.2 标签平滑
为了使用源分类器对目标表示进行分类,目标编码器需要模仿源编码器来输出表示。由于在此训练阶段没有使用任何监督损失,目标编码器可能无法生成一些原本一些有助于分类的差异化特征。
为了解决此问题,作者加入了一个「重建损失」(Reconstruction Loss)来确保目标编码器在对抗适应其特征时,能够保留其差异化性。
由于目标编码器是用源编码器初始化的,因此在域自适应之前,对于一个目标实例
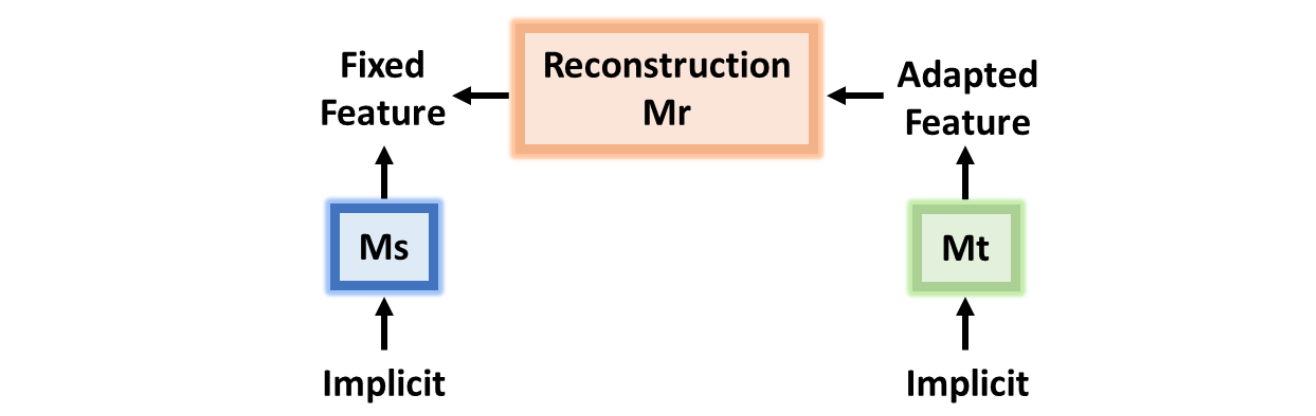
对于目标样本
其中
2.3 无监督目标函数
对于无监督的域自适应,完整的损失函数为
3. 训练
训练的过程可以分为三部分:预训练,对抗适应以及测试。
- 预训练期间,训练出源编码器
- 对抗适应期间,通过交替训练判别器
- 测试期间,将目标编码器和分类器进行测试。
二、实验过程
1. 设置
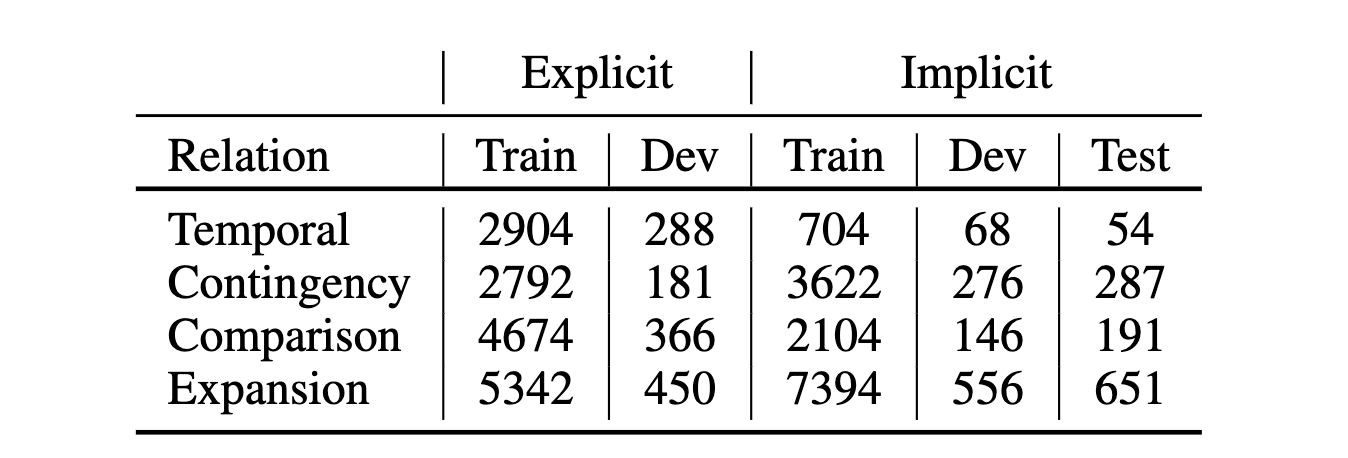
在实验数据方面,作者使用 PDTB 作为实验数据。其中训练集隐式关系为 21-22 小姐,显式关系来自 02-20 和 23-24 小节。显式和隐式的验证集来自 00-01 小节,数据分布情况如下
训练时,如果宏 F1不再改善,则早停。在预训练阶段,大概在 20 个 epochs 就需要早停,而在对抗适应阶段,早停大概发生在 5 个 epochs 之后。
在此模型中,超参数主要有分类器
2. 设置
3. 结果
为了评价模型,作者训练了 4 种分类器并且计算了每种类别以及全局的F1 分数,如下
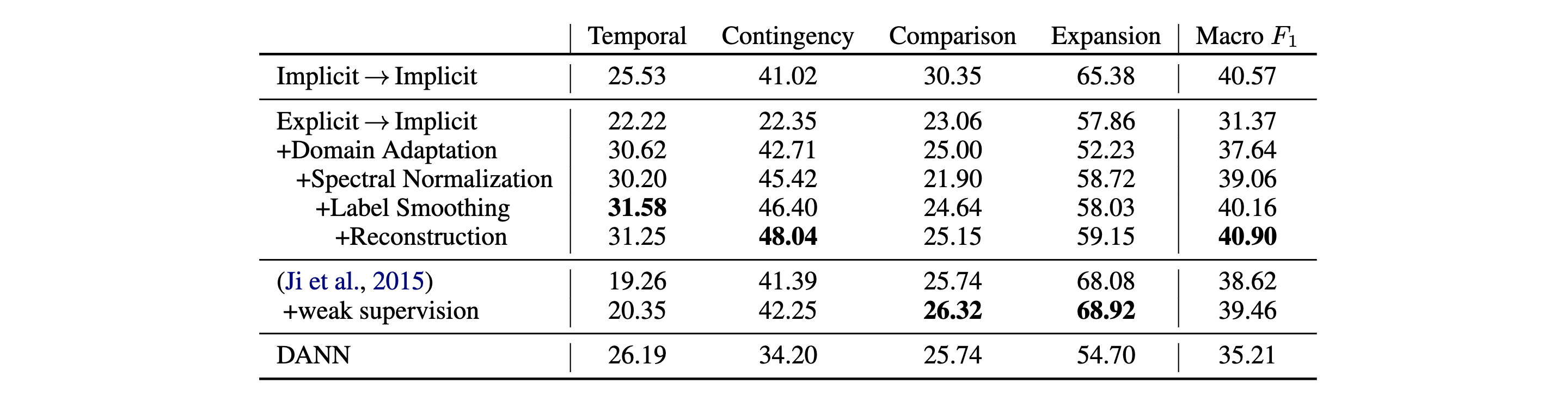
可见,此论文中的模型实现了最佳的平均 F1 分数,比起一般的「显式到隐式」,有高达
值得注意的是,在使用了域自适应后,「Expansion」的表现略有下降。作者怀疑这是因为 Expansion 的分布不同导致的。通过谱归一化,性能就有所改善了。
- 谱归一化改善了「Contingency」和「Expansion」的性能,而「Comparison」却下降了。
- 标签平滑改善了除了「Expansion」之外的所有关系的性能。
- 重建损失改善了除了「Temporal」之外的所有关系的性能。
总的来说,同时应用这三种 trick 可以得到最好的性能