P-R 曲线
如果希望将好瓜尽可能筛选出来,则可以增加瓜的数量来实现,如果将所有西瓜都选上,则查全率为 1,而查准率会偏低;反之,若过希望选出的瓜中好瓜比例高,则可只挑有把握的瓜,这会漏掉不少好瓜,使得查全率较低。如何综合考虑查准率和查全率?
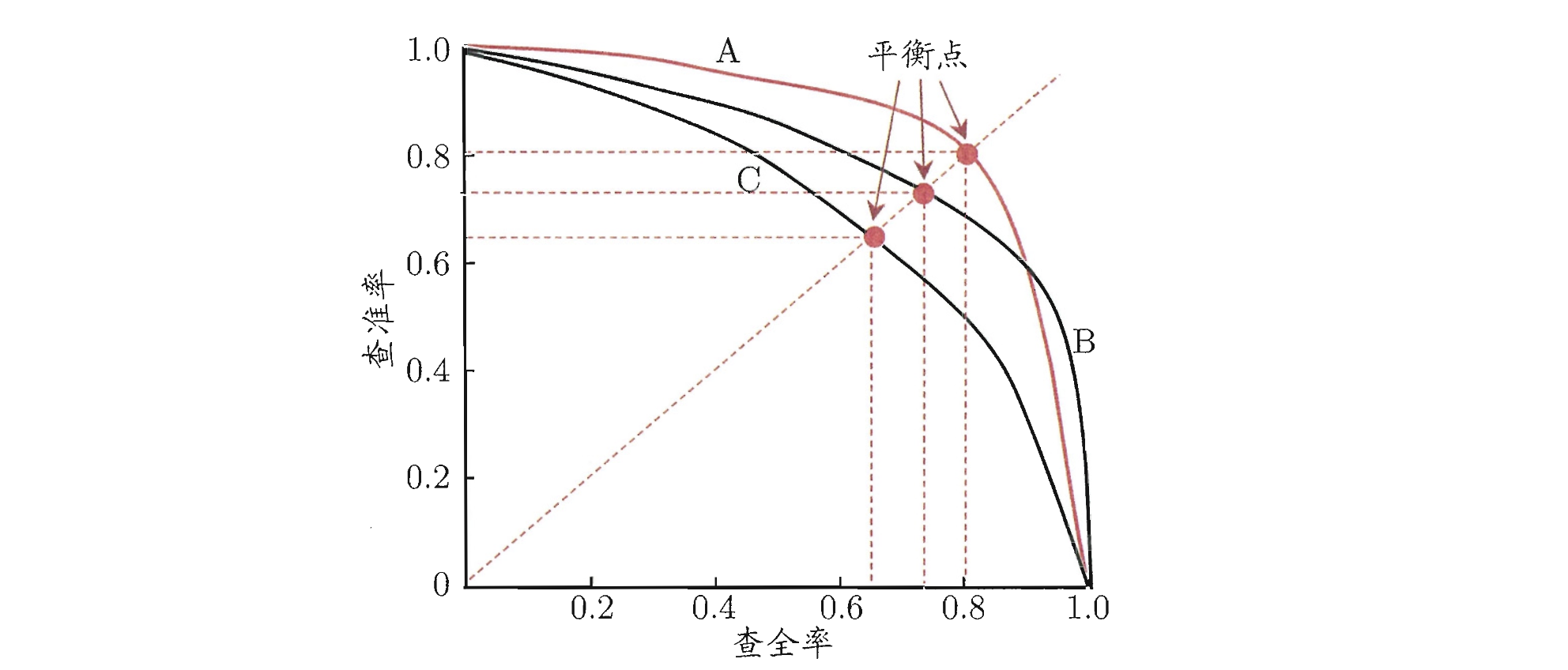
根据学习器的预测结果对样本进行排序,将学习器认为“最可能”是正例的样本排在前面,将“最不可能”是正例的样本排在最后;按此顺序逐个把样本作为正例进行预测,每次都计算当前的查全率和查准率,从而得到「P-R 曲线」
注意,P-R 曲线一定过
若一个学习器的 P-R 曲线被另一个学习器的曲线完全“包住”,则后者的性能好于前者;若两者较差,则无法判断。如上图,A 和 B 的性能好于 C,但是 A 和 B 之间的性能好坏无法判断。
当查准率=查全率时的取值称为「平衡点」(Break-Even,Point,BEP)。
根据学习器的预测结果对样本进行排序。以某个「截断点」(Cut Point)将样本判为正例和反例。根据任务需求采用不同的阶段点,若更重视查准率,则选择排序中靠前的位置进行截断;若更重视查全率,则选择靠后的位置进行截断。因此,排序本身对质量好坏,体现了综合考虑学习器在不同任务下的期望泛化性能的好坏
Interactive Graph
Table Of Contents