course:
- 数据挖掘
- 机器学习概念
「DBSCAN」(Density-Based Spatial Clustering of Applications with Noise,基于高密度连接区域的密度聚类方法)是一种著名的密度聚类算法。它基于一组「邻域函数」(
与划分和层次聚类方法不同,DBSCAN 将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有噪声的空间数据库中发现任意形状的聚类
对
核心对象
若
直接密度可达
给定一个对象集合
密度可达
若
密度相连
对
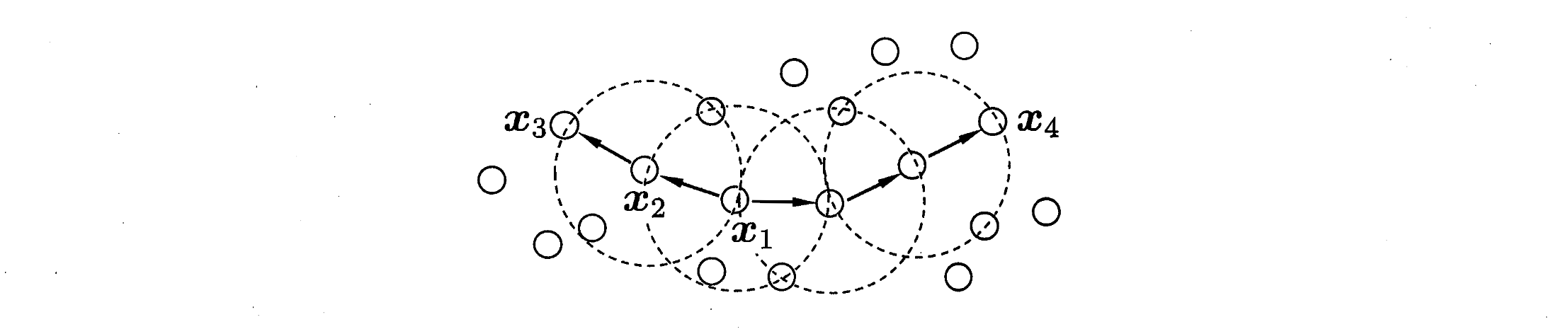
如图,
由密度可达关系到出的最大相连样本集合被定义为「簇」。给定邻域参数
- 连接性(Connectivity):
- 最大性(Maximality):
若以由 密 度 可 达
算法
先任选数据集中的一个核心对象为「种子」,再由此出发确定相应的聚类簇。
以任一核心对象为出发点,找出由其密度可达的样本生成聚类簇,然后更新核心对象集合(在集合中去除生成的聚类簇中包含的核心对象),重复上述操作,直到所有核心对象均被访问过为止。
输入:样本集
输出:簇划分
过程:
- 初始化核心对象集合
- 确定样本
- 将样本
- 将样本
- end if
- 确定样本
- end for
- 初始化聚类簇数
- 初始化为访问样本集合
- while
- 取出队列 Q 中首个样本
- if
- 令
- 将
- 令
- end if
- 取出队列 Q 中首个样本
- end while
DBSCAN 将数据对象分为三类
- 核心对象(Core Object):
- 边缘对象(Border Object):非核心对象,但位于某个核心对象邻域内
- 离群对象(Outlier):亦称为噪声对象,非核心对象,亦非边缘对象
特点
优点:
- 可以发现任意形状的聚类簇
- 自动发现簇的数量
- 有效处理数据集中的噪声数据
- 对数据输入顺序不敏感
缺点:
- 对输入参数
- 输入参数
- 只能发现密度相仿的簇
- 计算复杂度
例子
例 1
假设现在有 7 个点
解:
首先找出所有核心对象,为
此时
例 2
下面以西瓜数据集为例演示 DBSCAN 的过程,设置
- DBSCAN 首先确定核心对象集合
然后随机选择一个核心对象作为种子。假设选择核心对象
然后 DBSCAN 将
再从更新后的集合