course:
- 机器学习定义
CFSFDP 即基于密度峰值的聚类算法,是一种密度聚类。其基本思想为
- 聚类中心的密度大,且其密度均大于其邻居的密度。
- 聚类中心与其他密度更大的点的距离相对较大。
对第
定义「局部密度」为
参数
定义距离为
由以上公式可知,当第
聚类中心选择
计算数据集中每个样本点的局部密度和距离,可以得到
- 聚类中心 L 同时具有较大的
- 离群点:
聚类过程:聚类中心找到以后,剩余的每个样本被归属到它的有更高密度的最邻近所属类簇,类簇分配只需要一步即可完成,不像其他函数需要对目标函数进行优化
聚类中心选择算法优化
对于图 A 中的情形,无法准确判断聚类中心,可以采用一个将
显然,
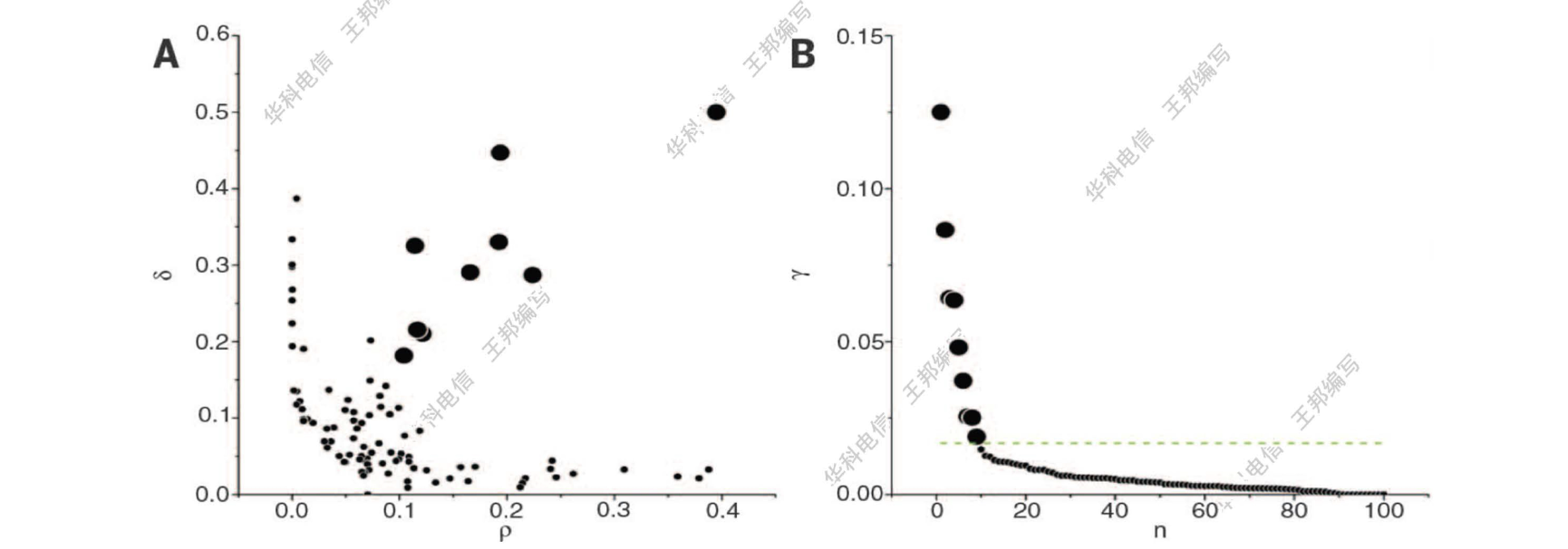
离群点算法优化
根据前面介绍的聚类算法,一些分散的离群点也会被强制分类到类簇当中,造成聚类后类簇边界不清晰,影响聚类效果
为了改进这种情况,将样本点划分为「核心区域」(Cluster Core)和「光环部分」(Cluster Halo),具体划分方法为
- 查找边界区域:若一个类簇的样本
- 计算临界密度:为每个类簇找到其边界区域中平均局部密度最高的点
- 划分核心部分与光环部分:类簇中样本的局部密度大于
Interactive Graph
Table Of Contents