算法
AdaBoost是一种最常用的Boosting 算法。AdaBoos t的核心思想是根据前一个基本分类器的错误率来调整每个样本的权重,使得之前被错误分类的样本在后续的分类器中得到更多的关注。同时,每个基本分类器都会被赋予一个权重,这个权重与它的准确性有关。最终的模型是这些加权分类器的组合。
输入:训练集
输出:
过程:
- 初始化样本分布
- 基于分布
- 估计
- 确定分类器
- 更新样本分布
- 基于分布
第一个基分类器
图示
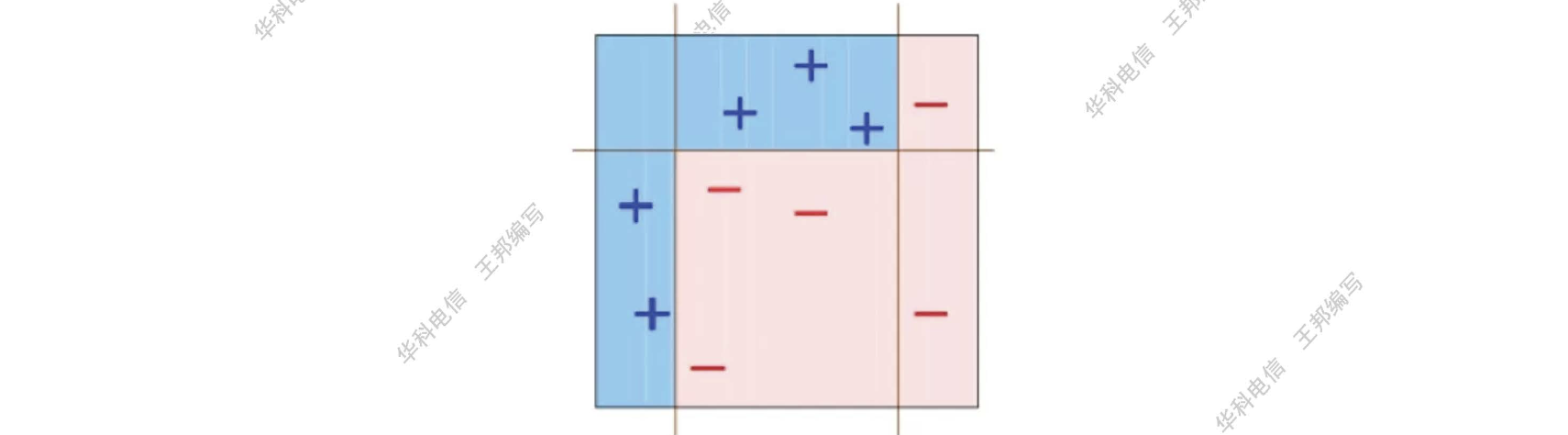
举一个简单的例子来看看 AdaBoost 的实现过程。图中共 10 个训练数据,其中 + 和 - 分别表示两种类别。基分类器使用水平或垂直直线来进行分类。
开始每个样本的权值设为
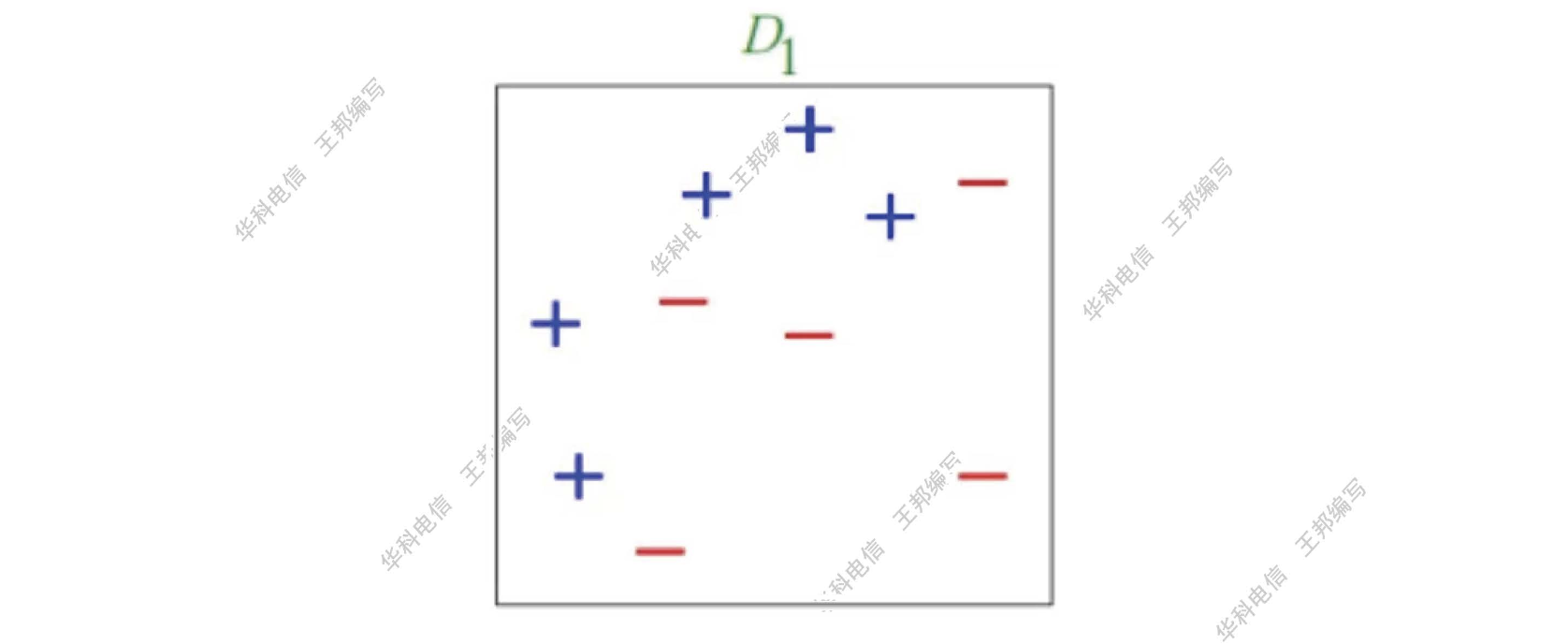
第一个分类器
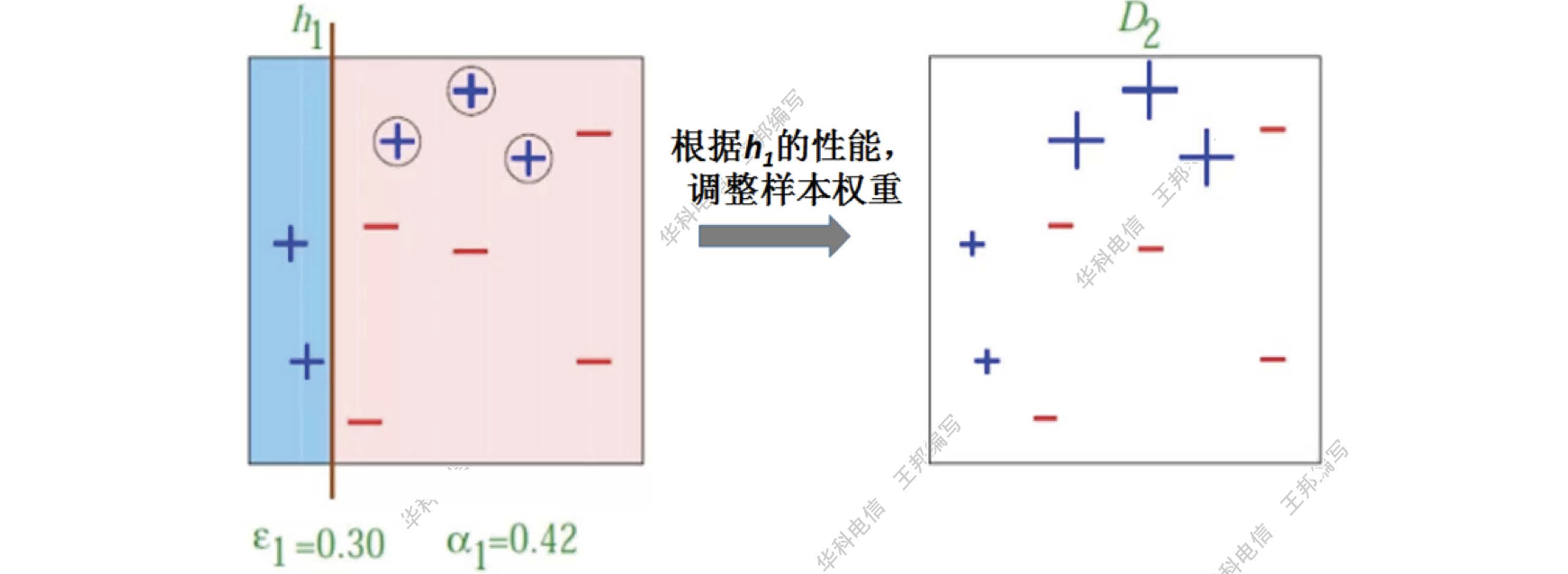
第二个分类器
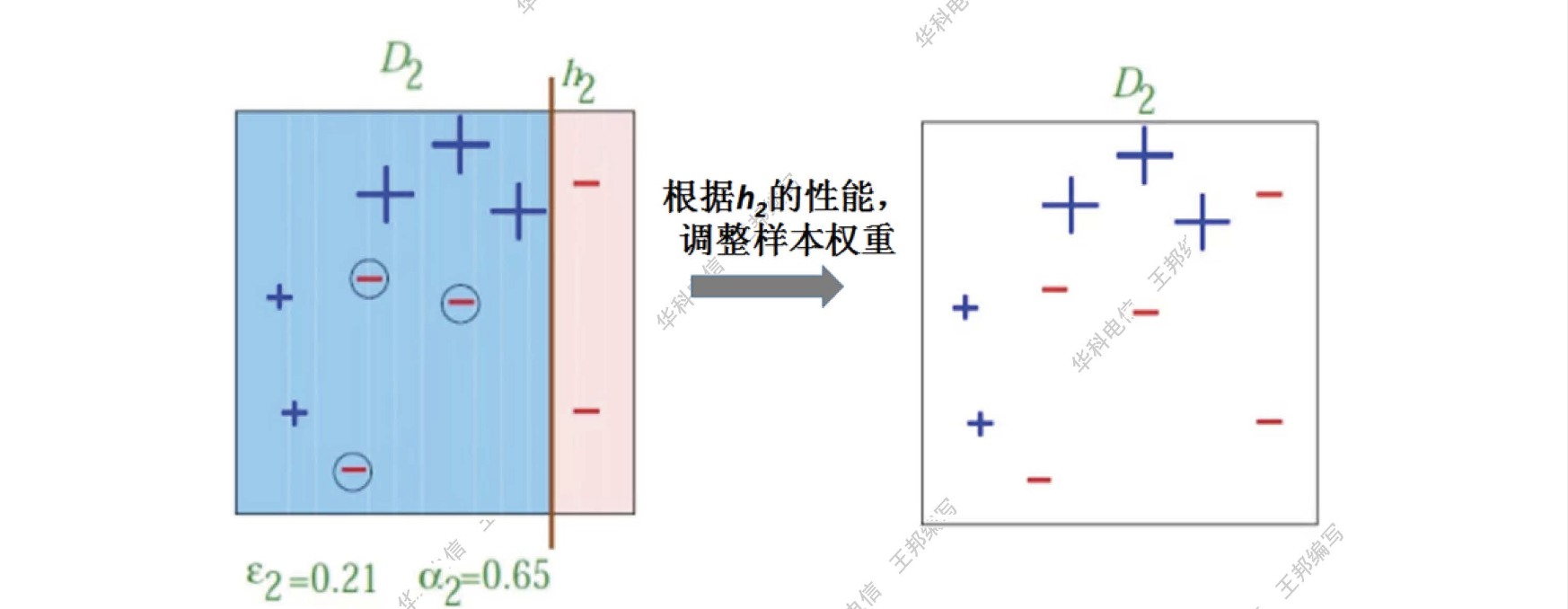
第三个分类器
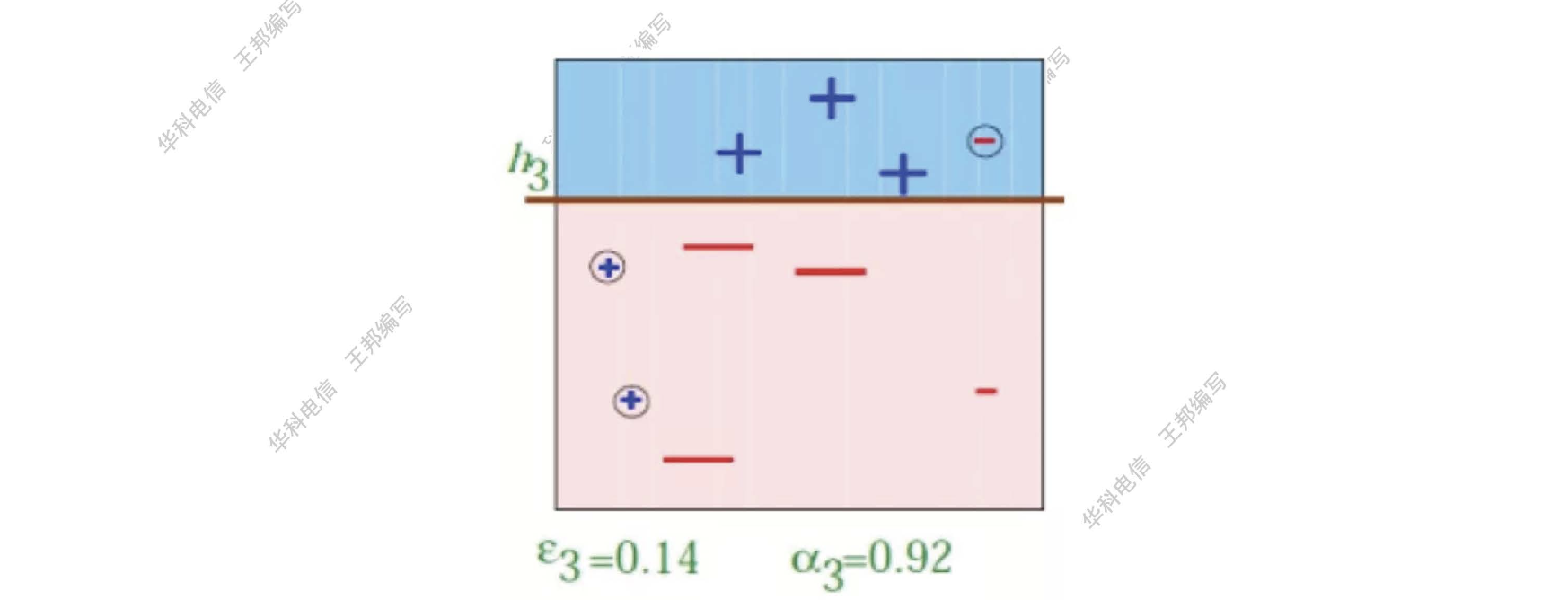
将上述三个分类器经过线性加权,得到最终的分类器
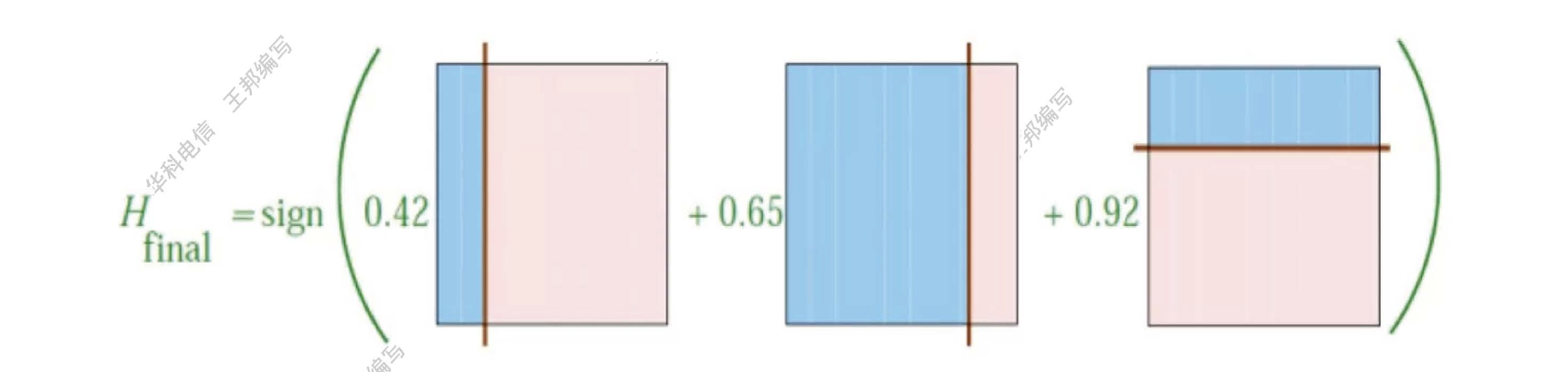
使用这个最终分类器对最初的样本进行分类,得到结果如下
例题
给定下列样本,使用简单的基于阈值比较的基学习器,用 Adaboost 算法学习一个强分类器
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | +1 | +1 | +1 | -1 | -1 | -1 | +1 | +1 | +1 | -1 |
解:初始化数据权值分布为
可以发现,
更新训练数据的权值分布,产生
归一化结果为
利用计算
得到序列
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| +1 | +1 | +1 | -1 | -1 | -1 | +1 | +1 | +1 | -1 | |
| .1 | .1 | .1 | .1 | .1 | .1 | .1 | .1 | .1 | .1 | |
| +1 | +1 | +1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | |
| .0655 | .0655 | .0655 | 0.655 | 0.655 | 0.655 | .1527 | .1527 | .1527 | .0655 | |
| .0715 | .0715 | .0715 | .0715 | .0715 | .0715 | .1666 | .1666 | .1666 | .0715 | |
| .4236 | .4236 | .4236 | .4236 | .4236 | .4236 | .4236 | .4236 | .4236 | .4236 | |
| +1 | +1 | +1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 |
综上,第一次集成的学习器为
其中
第二次迭代,基于
在权值分布为
然后计算新分类器
第二次迭代后得到的第二个分类器可表示为
其中